728x90
인터폴레이션 탐색이란?
인터폴레이션 탐색(Interpolation Search)은 정렬된 데이터 집합에서 값을 찾는 고급 탐색 알고리즘입니다. 이 방법은 이진 탐색을 개선하여, 데이터의 분포를 고려하여 탐색 위치를 예측하고, 그 예측 위치에서 시작하여 탐색하는 기법입니다.
인터폴레이션 탐색의 작동 원리
인터폴레이션 탐색은 데이터 집합의 최소값과 최대값 사이의 비율을 이용하여 탐색할 위치를 예측합니다. 이는 찾고자 하는 키 값이 데이터 집합 내에서 어디에 위치해 있을지 추정하여, 더 적절한 시작점에서 탐색을 시작하게 합니다.
인터폴레이션 탐색의 단계별 과정
- 데이터 집합의 최소 인덱스(min)와 최대 인덱스(max)를 정합니다.
- 찾고자 하는 값(target)의 위치를 예측하여 중앙 인덱스(mid)를 계산합니다.
- 예측된 위치의 값과 target을 비교합니다.
- target이 예측된 위치의 값보다 작으면, max를 mid - 1로 조정합니다.
- target이 예측된 위치의 값보다 크면, min을 mid + 1로 조정합니다.
- target이 예측된 위치의 값과 동일하면, 탐색을 종료하고 mid를 반환합니다.
- min > max가 될 때까지 위의 과정을 반복합니다. 찾고자 하는 값이 없는 경우, 탐색 실패를 나타내는 값을 반환합니다.
인터폴레이션 탐색의 복잡도
시간 복잡도: 데이터가 균일하게 분포되어 있을 경우 최선의 경우 O(log log n), 하지만 최악의 경우 O(n)입니다.
공간 복잡도: O(1)로, 추가적인 메모리 공간이 필요 없습니다.
Pseudocode
function interpolationSearch(arr, target) {
let low = 0
let high = arr.length - 1
while (low <= high && target >= arr[low] && target <= arr[high]) {
let pos = low + ((target - arr[low]) * (high - low) / (arr[high] - arr[low]))
if (arr[pos] == target) {
return pos
}
if (arr[pos] < target) {
low = pos + 1
} else {
high = pos - 1
}
}
return -1 // 탐색 실패
}
실제 예시로 이해하기
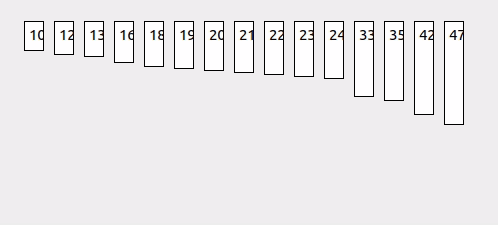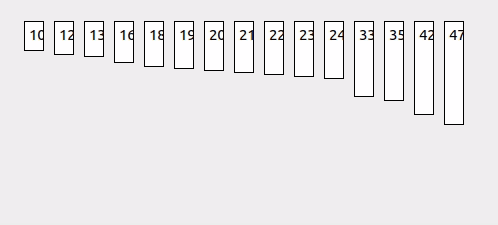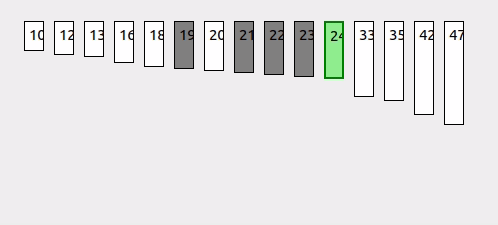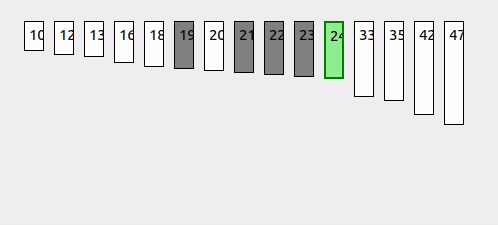
예를 들어, [10, 12, 13, 16, 18, 19, 20, 21, 22, 23] 배열에서 값 19를 찾고자 한다고 가정해봅시다.
- 초기 low = 0, high = 9로 설정합니다.
- 예측된 pos를 계산하고, arr[pos]와 target을 비교합니다.
- pos에서 찾고자 하는 값 19를 발견하므로 탐색을 종료하고 pos를 반환합니다.
인터폴레이션 탐색은 데이터가 균일하게 분포되어 있을 때 매우 빠른 탐색 속도를 제공합니다. 하지만 데이터 분포가 균일하지 않은 경우 이진 탐색보다 성능이 떨어질 수 있습니다. 따라서 데이터의 특성을 고려하여 적절한 탐색 기법을 선택하는 것이 중요합니다.